|
I am a researcher at ByteDance Seed. I obtained my Ph.D. degree from The Chinese University of Hong Kong MMLab, supervised by Prof. Dahua Lin. I got my bachelor's degree from School of Electronic Information and Electrical Engineering at Shanghai Jiao Tong University in 2021, supervised by Prof. Weiyao Lin. I am interested in computer vision and machine learning, especially self-supervised learning, video understanding and multi-modal large language models. Email / CV / Google Scholar / Github |

|
|
|
|
ByteDance Seed Model card, 2025 Project Page | PDF | cookbook |
|
ByteDance Seed Tech report, 2025 Project Page | arXiv | cookbook |
|
|
|
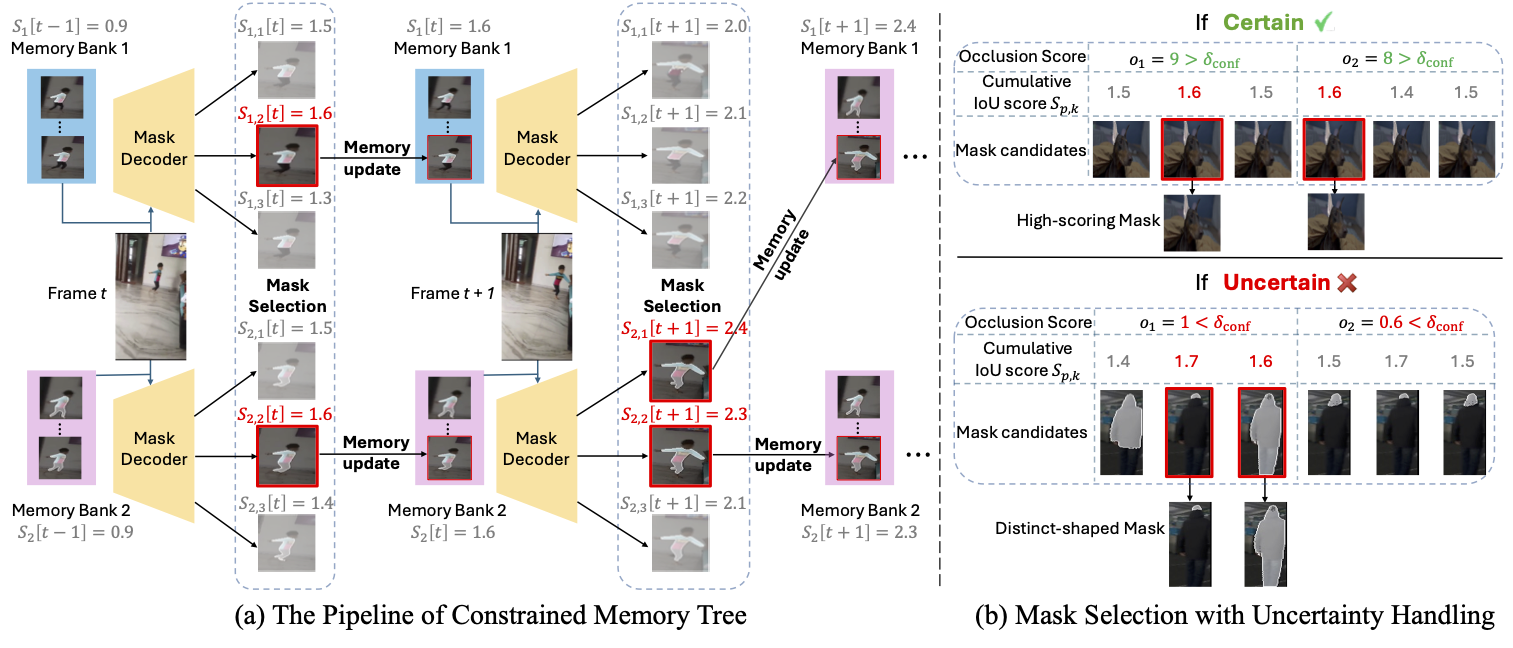
Shuangrui Ding, Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Yuwei Guo, Dahua Lin, Jiaqi Wang ICCV, 2025 Project Page | arXiv | code | PDF Outperform SAM 2 by a large margin through a training-free memory tree. |
|
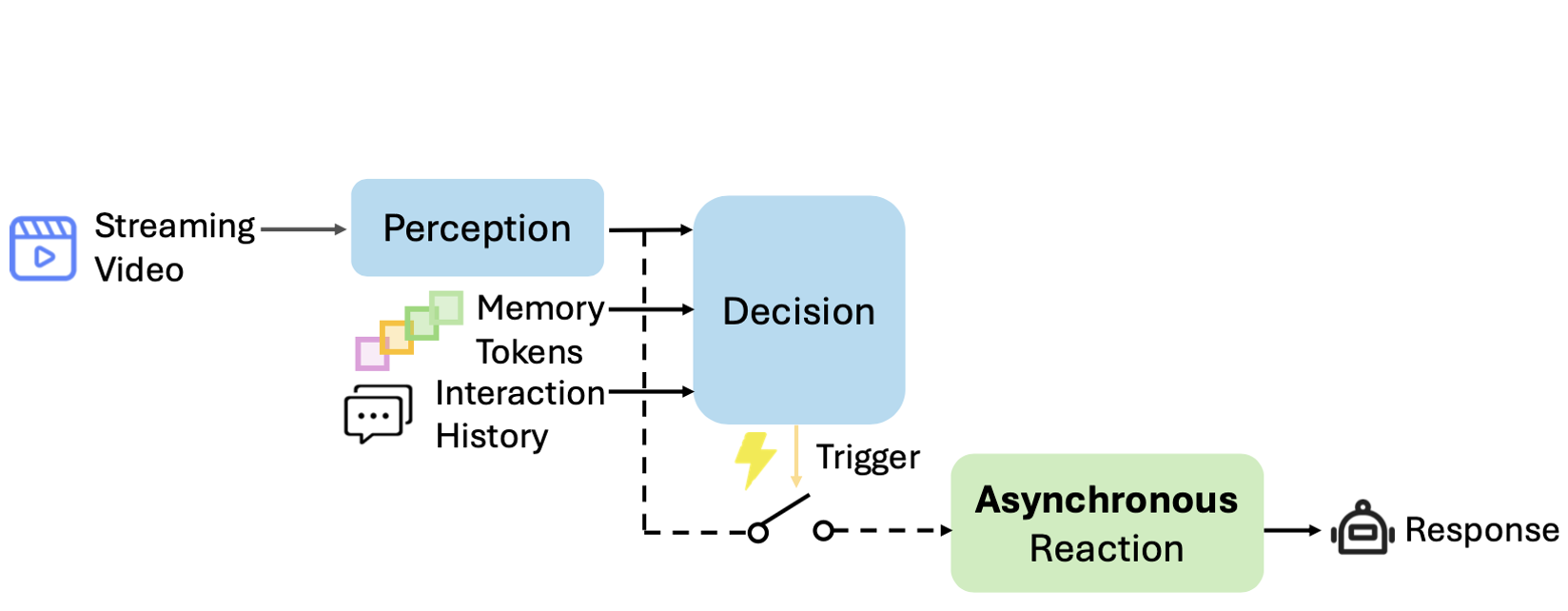
Rui Qian*, Shuangrui Ding*, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, Jiaqi Wang CVPR, 2025 arXiv / code Asynchronous operation of disentangled perception, decision, and reaction modules for online video LLMs. |
|
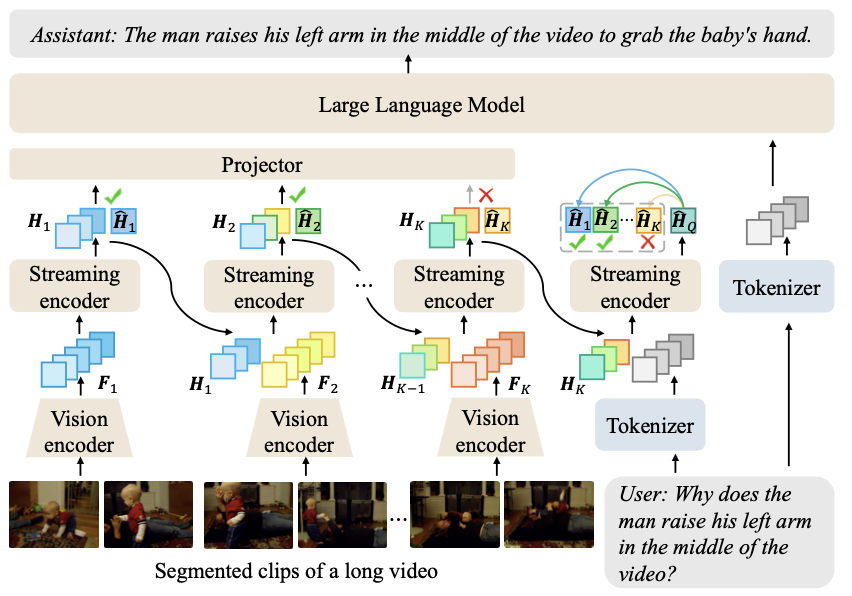
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang NeurIPS, 2024 arXiv Long video understanding with disentangled streaming video encoding and LLM reasoning. |
|
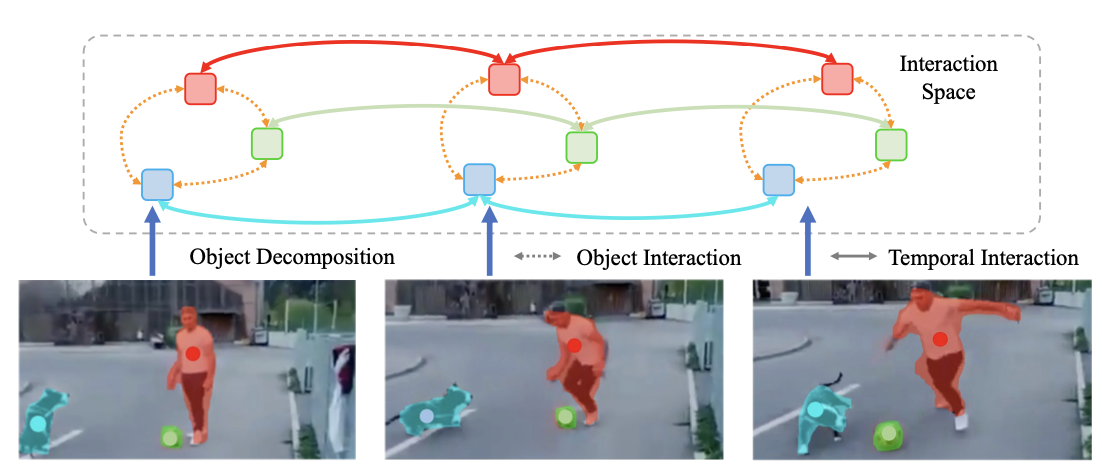
Rui Qian, Shuangrui Ding, Dahua Lin ECCV, 2024 Efficiently adapt image foundation models to video domain in an object-centric manner. |
|
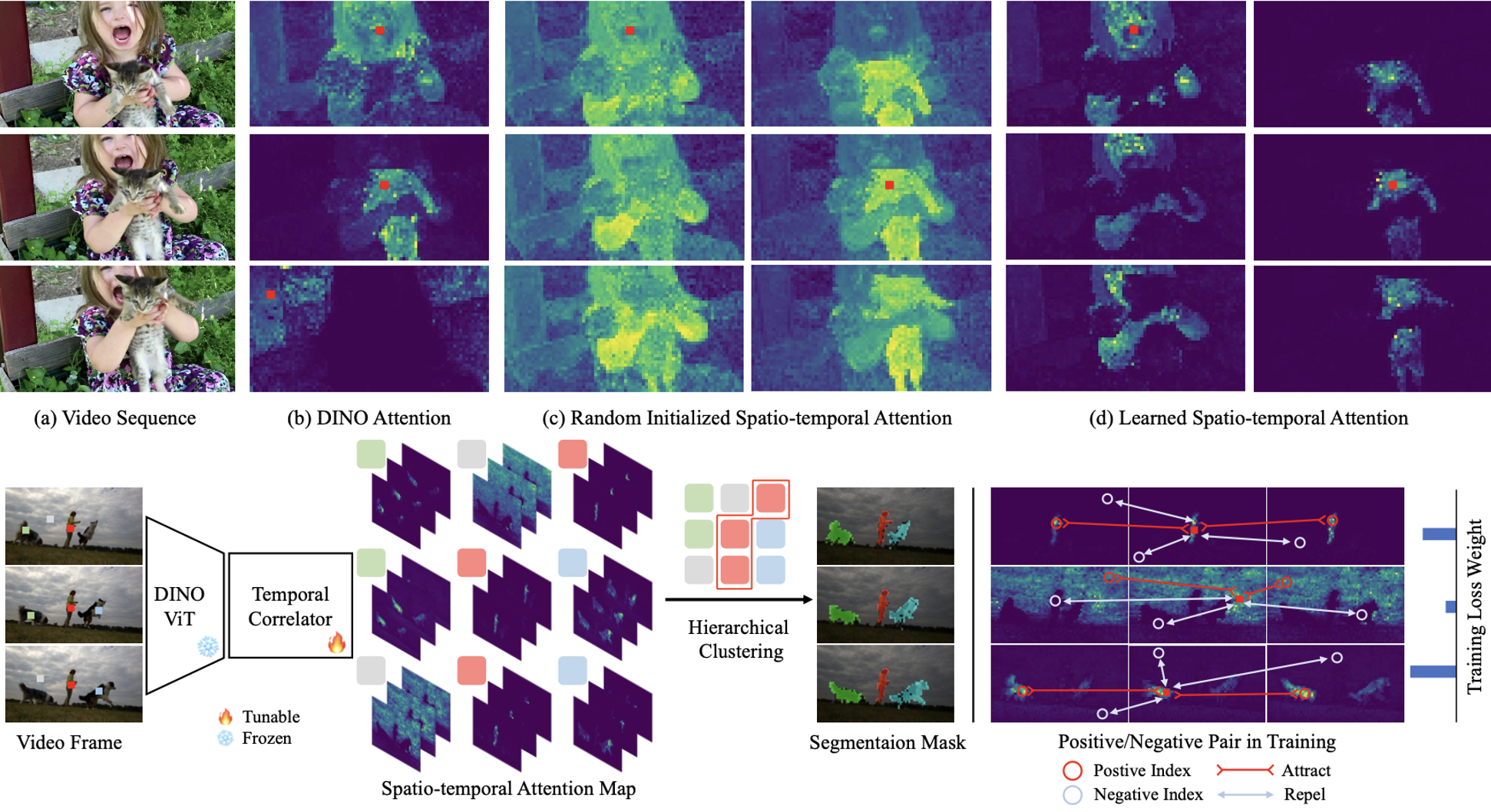
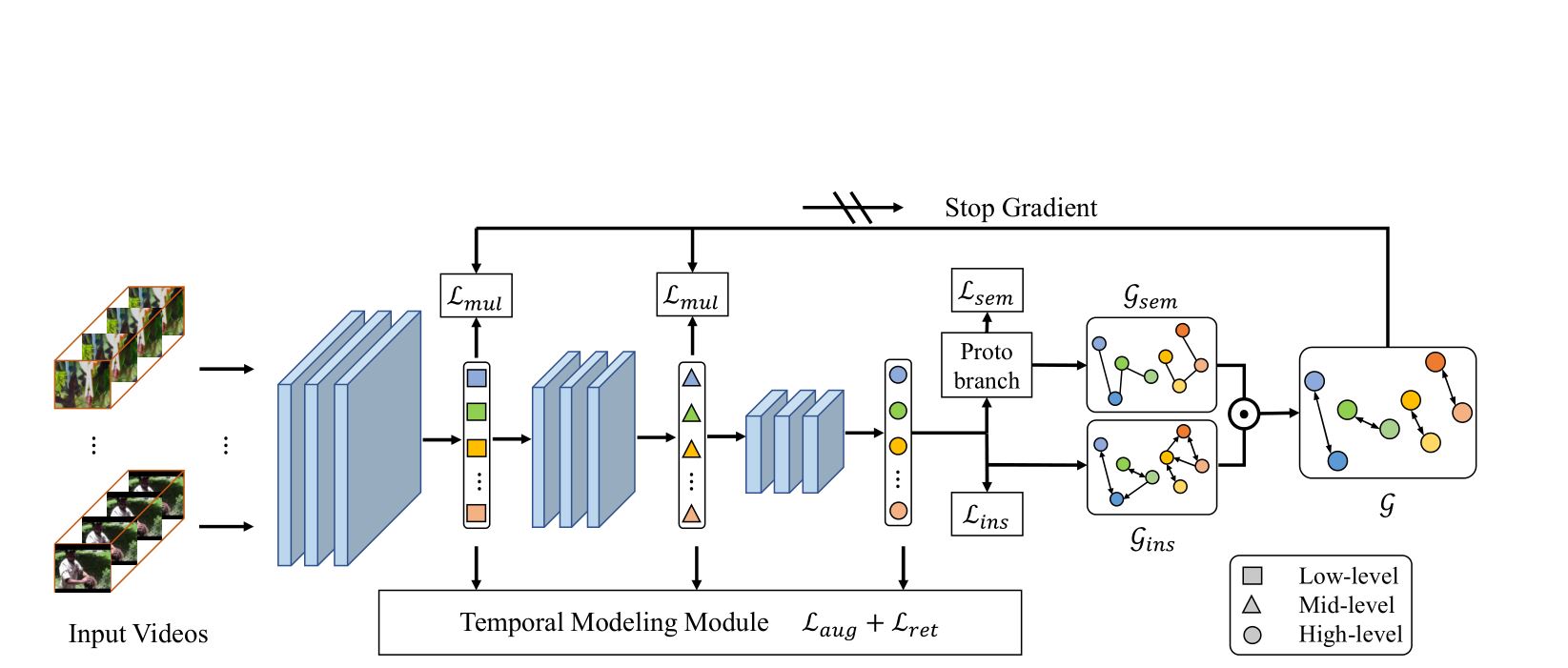
Shuangrui Ding*, Rui Qian*, Haohang Xu, Dahua Lin, Hongkai Xiong ECCV, 2024 arXiv, code Learn robust spatio-temporal corrependence on top of DINO-pretrained Transformer without any annotation. |
|
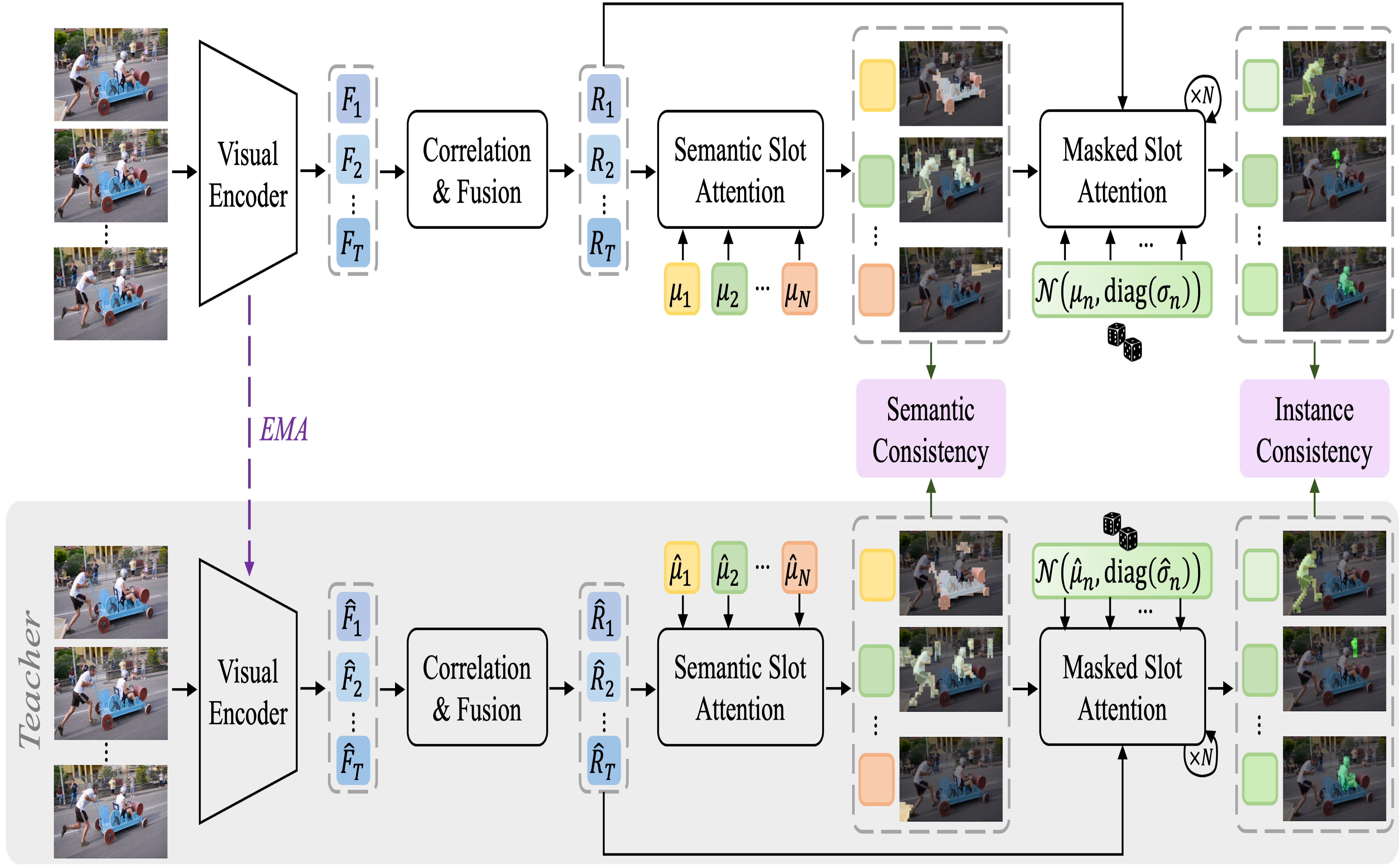
Rui Qian, Shuangrui Ding, Xian Liu, Dahua Lin ICCV, 2023 arXiv, pdf, code Jointly utilizes high-level semantics and low-level temporal correspondence for object-centric learning in videos without any supervision. |
|
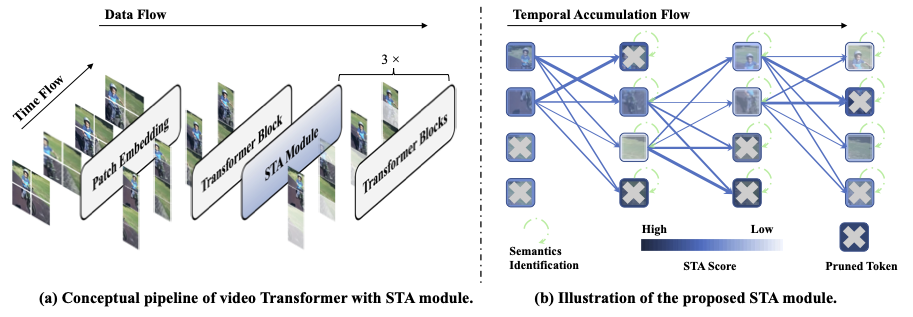
Shuangrui Ding, Peisen Zhao, Xiaopeng Zhang, Rui Qian, Hongkai Xiong, Qi Tian ICCV, 2023 Project page, arXiv, pdf, code Propose token pruning strategy for video Transformers to offer a competitive speed-accuracy trade-off without additional training or parameters. |
|
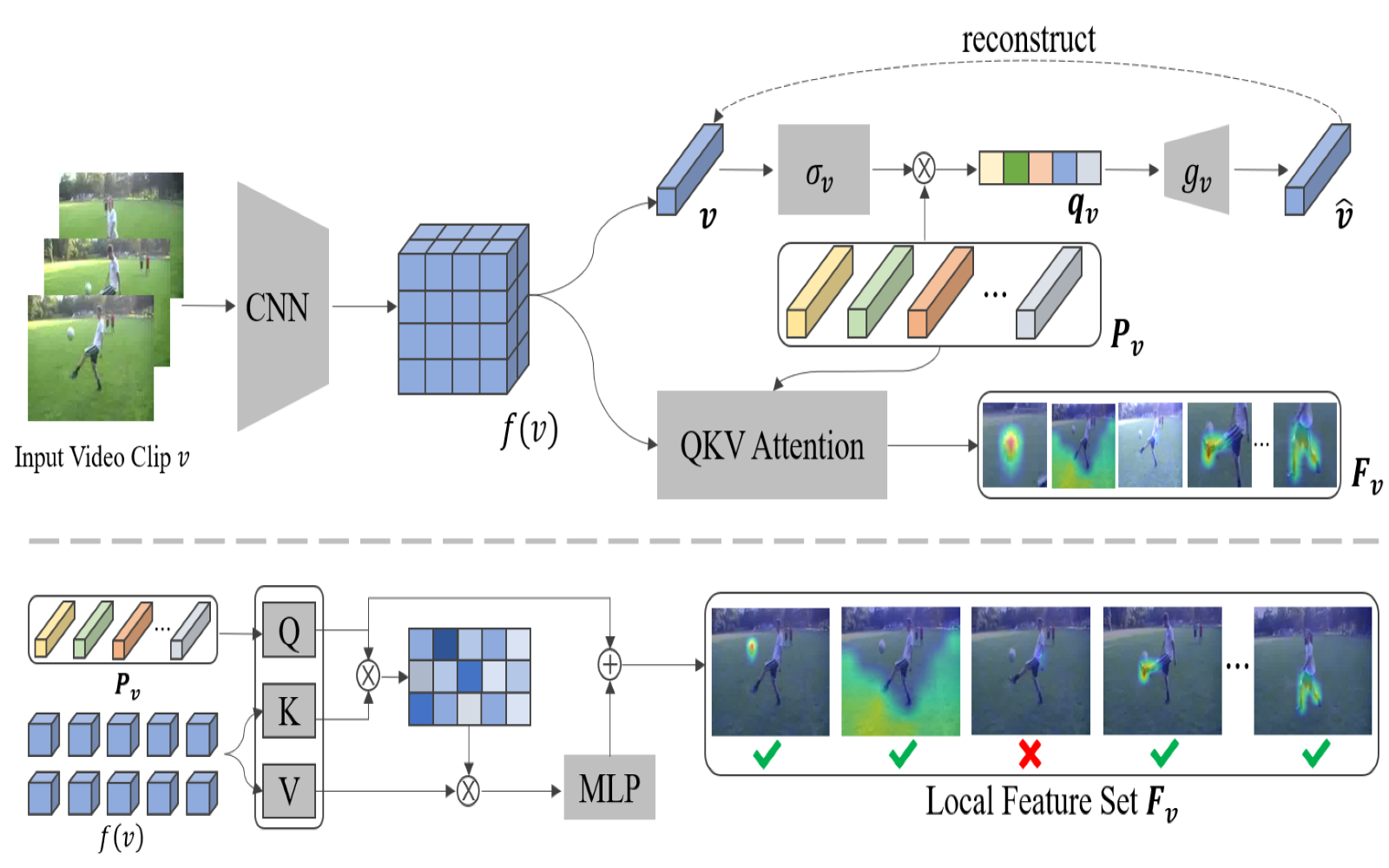
Rui Qian, Shuangrui Ding, Xian Liu, Dahua Lin ECCV, 2022 arXiv, code Learn static and dynamic visual concepts in videos to aggregate local patterns with similar semantics to boost unsupervised video representation. |
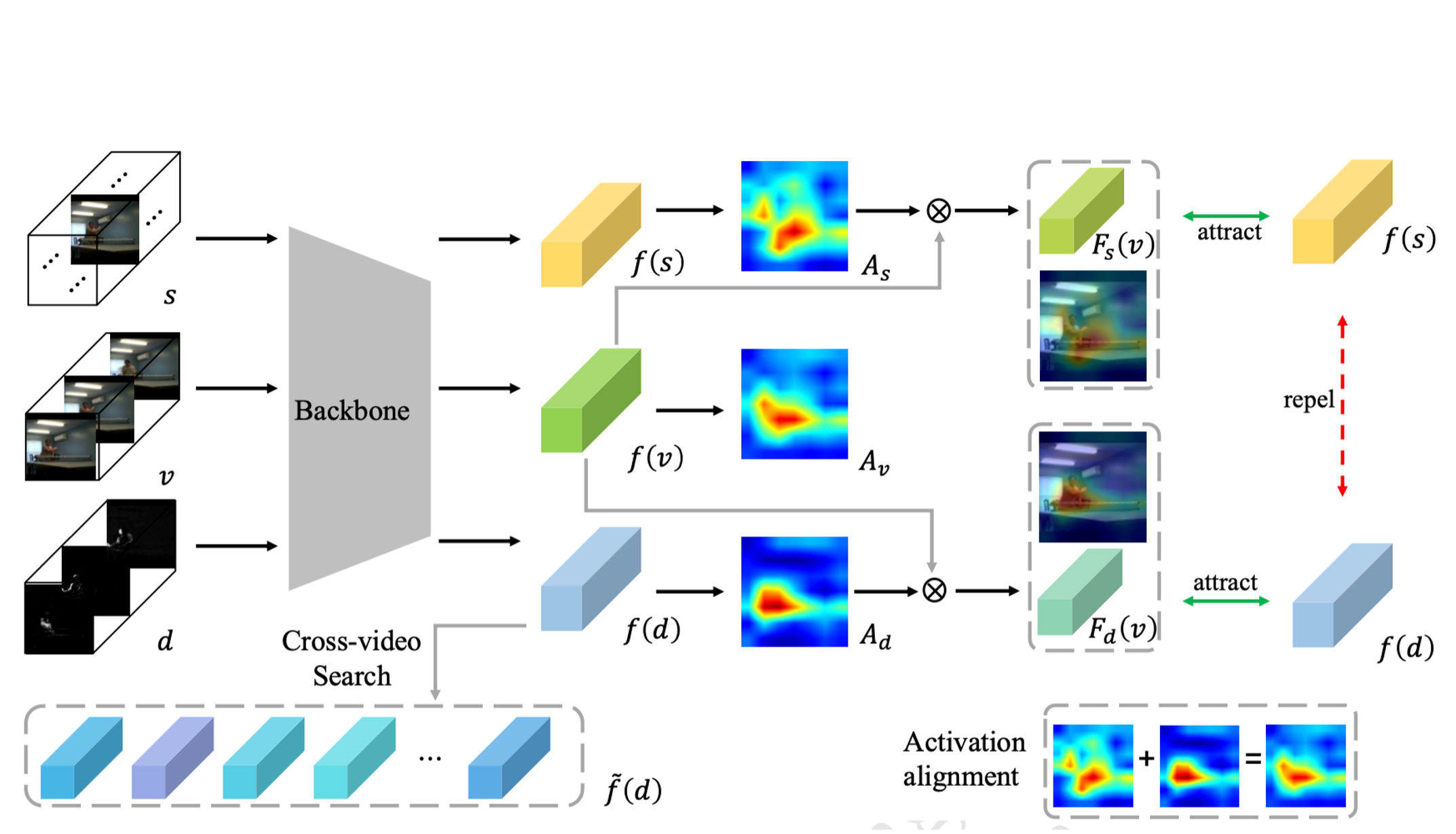
|
Shuangrui Ding, Rui Qian, Hongkai Xiong ACM MM, 2022 arXiv, code A novel dual contrastive formulation is presented to decouple the static/dynamic features and thus mitigate the background bias. |
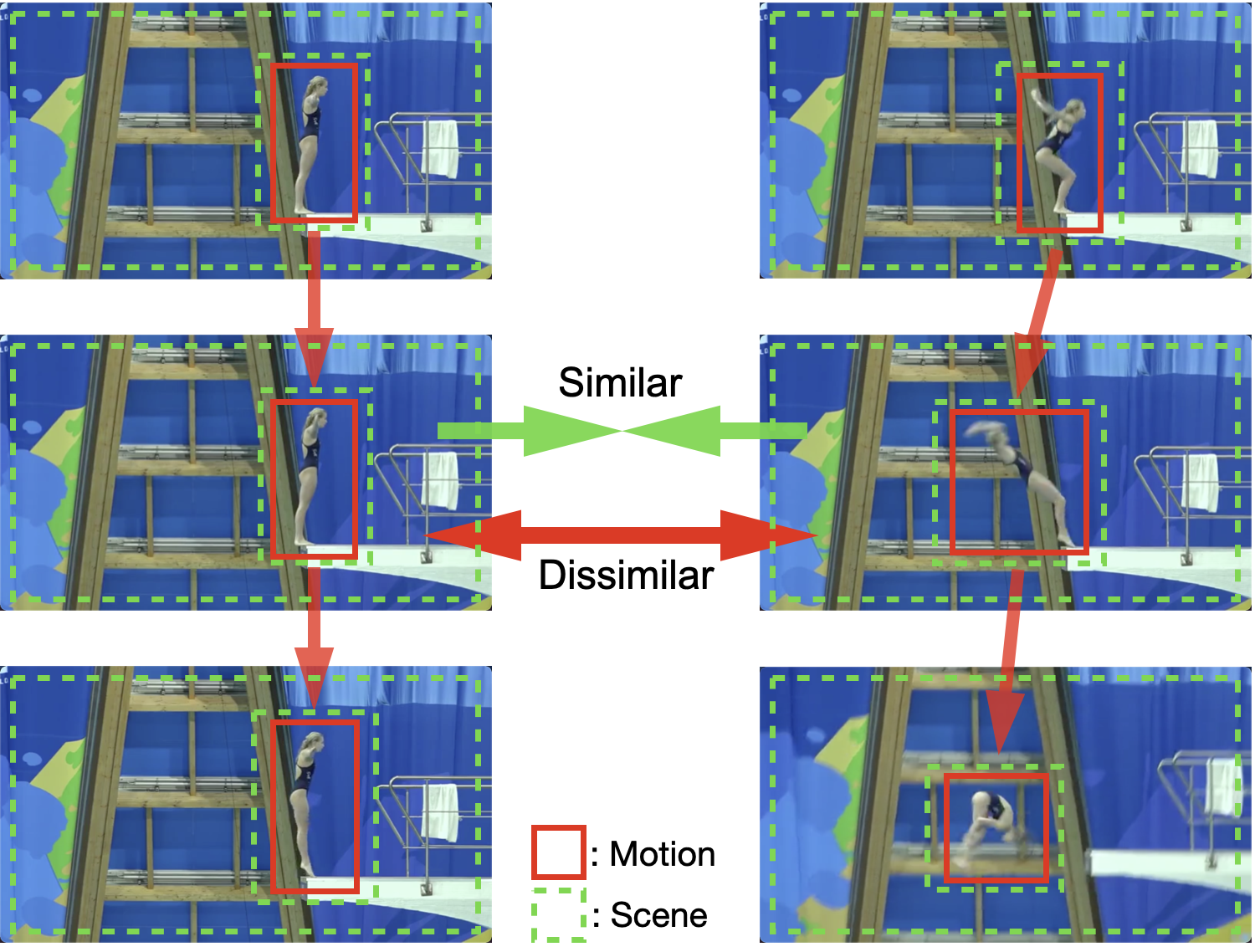
|
Shuangrui Ding, Maomao Li, Tianyu Yang, Rui Qian, Haohang Xu, Qingyi Chen, Jue Wang, Hongkai Xiong CVPR, 2022 Project page, arXiv, code, Chinese coverage Mitigate the background bias in self-supervised video representation learning via copy-pasting the foreground onto the other backgrounds. |

|
Xian Liu*, Rui Qian*, Hang Zhou*, Di Hu, Weiyao Lin, Ziwei Liu, Bolei Zhou, Xiaowei Zhou AAAI, 2022 arXiv Erase the interference in general multi-modal scenes for robust visual sound localization. |
|
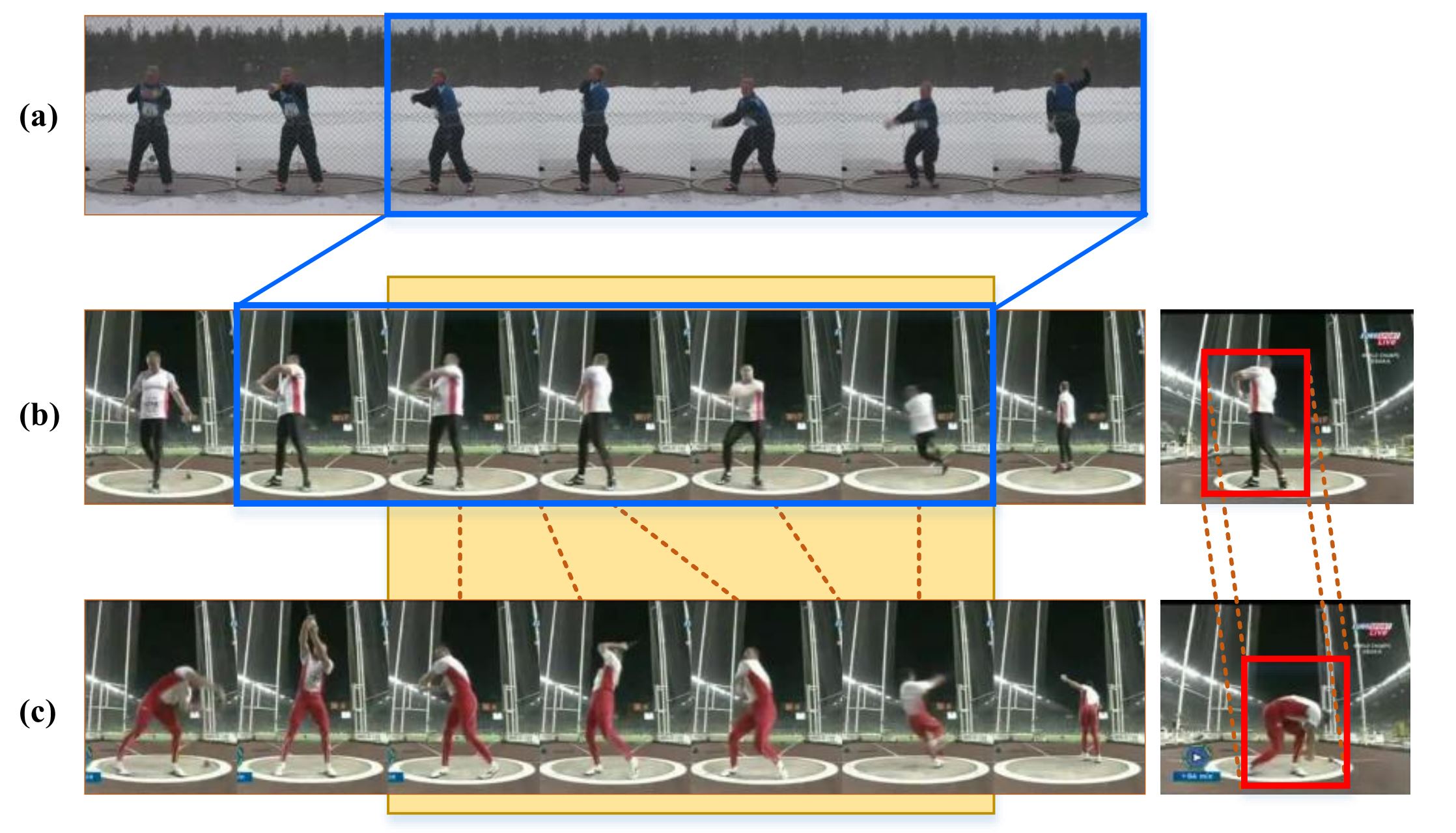
Shuyuan Li*, Huabin Liu*, Rui Qian, Yuxi Li, John See, Mengjuan Fei, Xiaoyuan Yu, Weiyao Lin AAAI, 2022 arXiv, code Solve action duration misalignment and action evolution misalignment in few-shot settings. |
|
Rui Qian, Yuxi Li, Huabin Liu, John See, Shuangrui Ding, Xian Liu, Dian Li, Weiyao Lin ICCV, 2021 arXiv, code Self-supervised video representation learning from the perspective of both high-level semantics and lower-level characteristics |
|
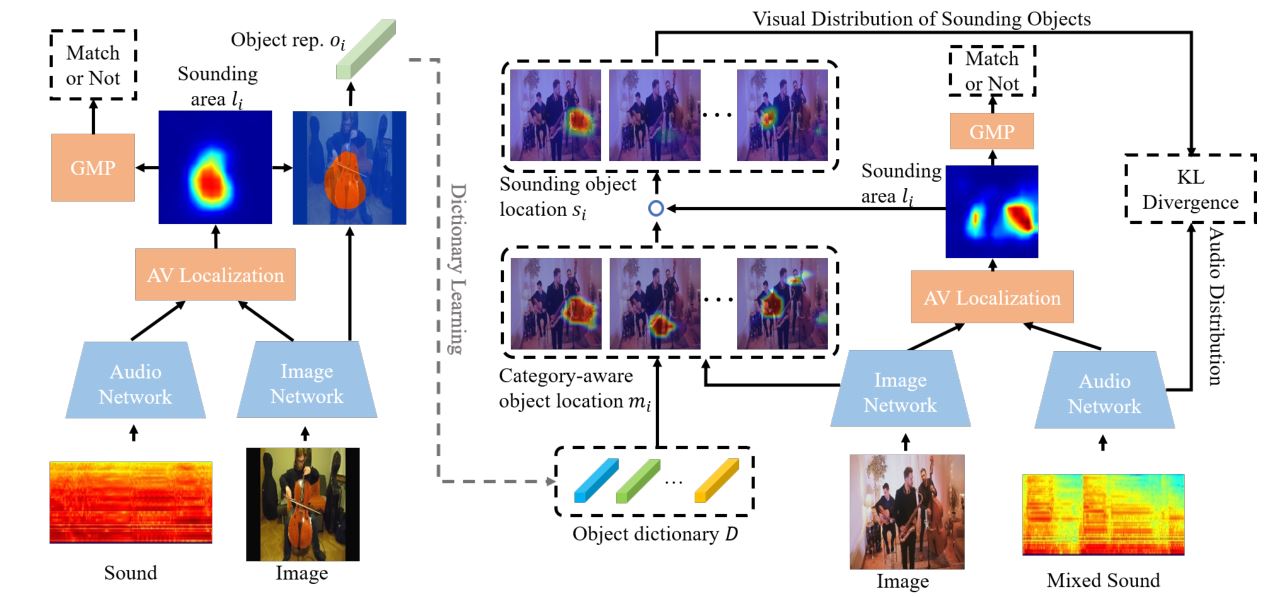
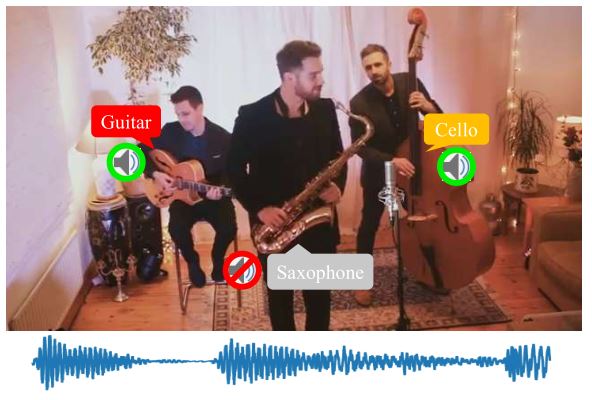
Di Hu, Rui Qian, Minyue Jiang, Tan Xiao, Shilei Wen, Errui Ding, Weiyao Lin, Dejing Dou NeurIPS, 2020 arXiv, code Discriminative sounding objects localization in cocktail-party scenario in a two-stage manner |
|
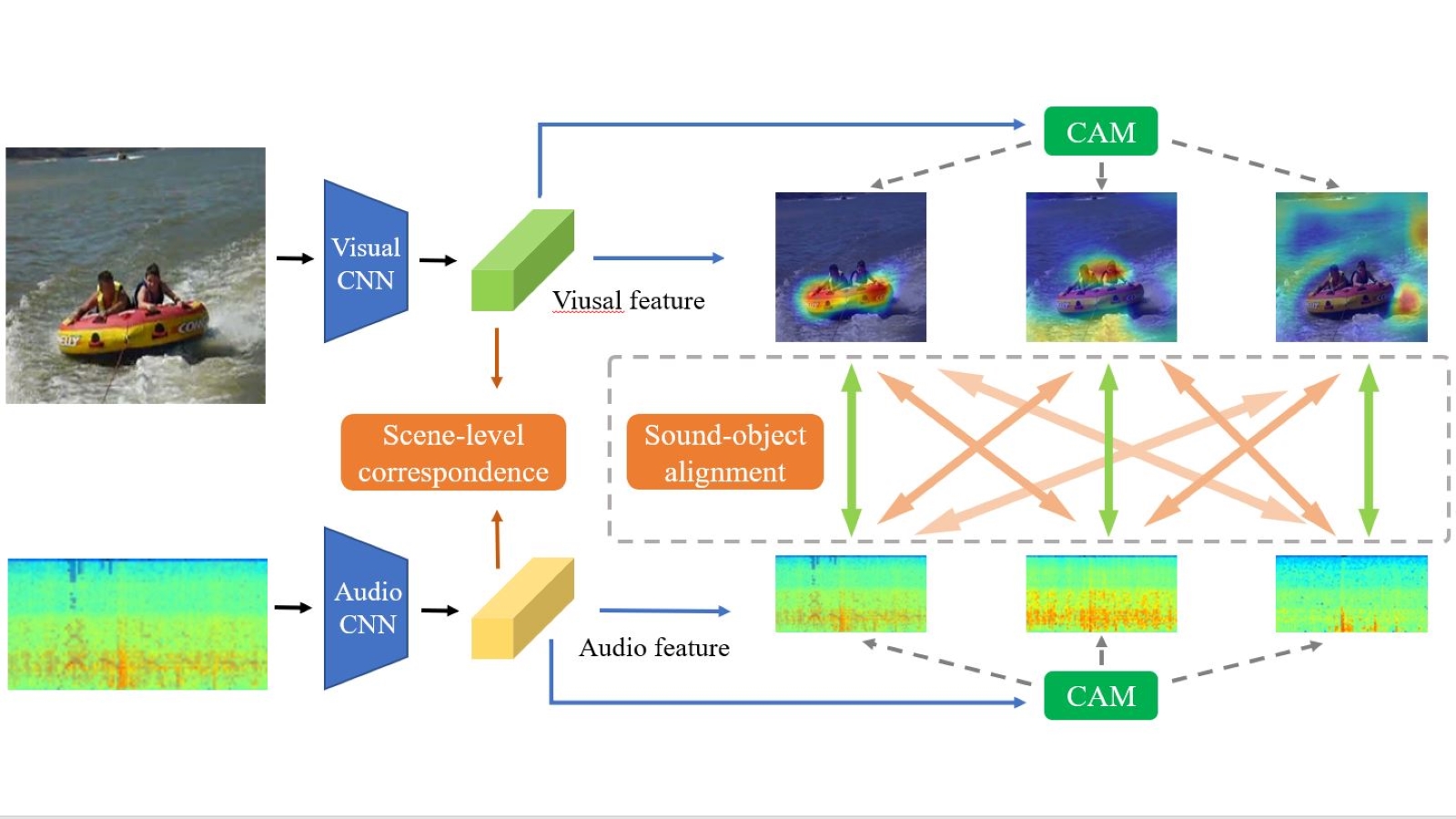
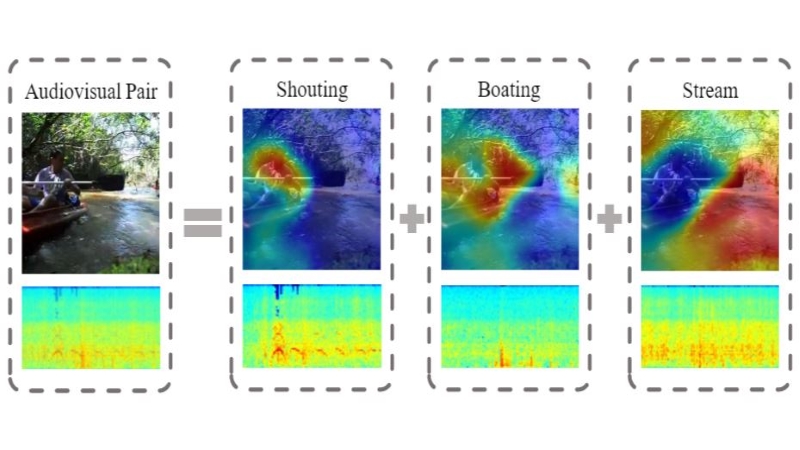
Rui Qian, Di Hu, Heinrich Dinkel, Mengyue Wu, Ning Xu, Weiyao Lin ECCV, 2020 arXiv, code Complex audiovisual scene understanding, to associate sound-object pairs from coarse to fine |
|
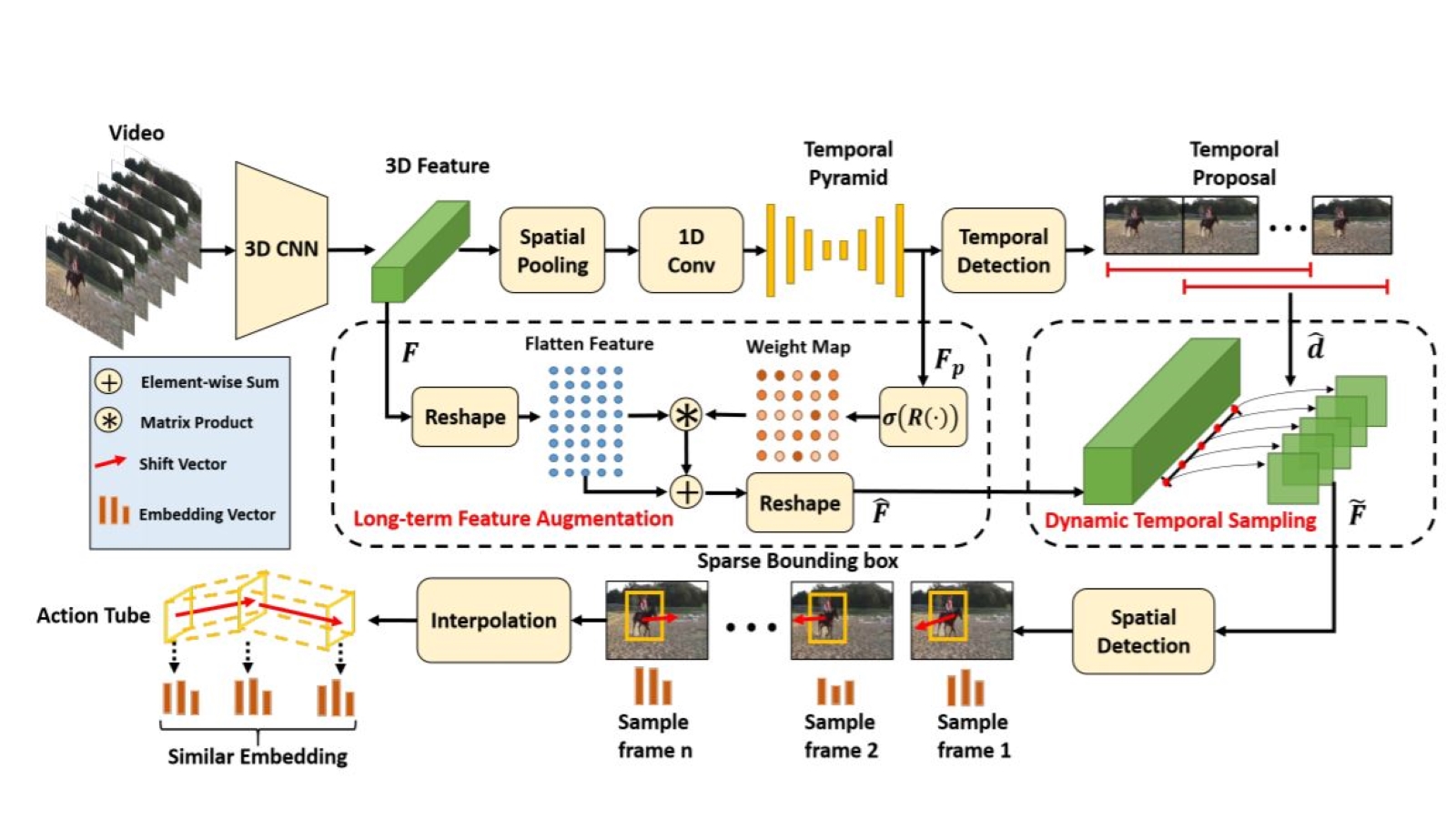
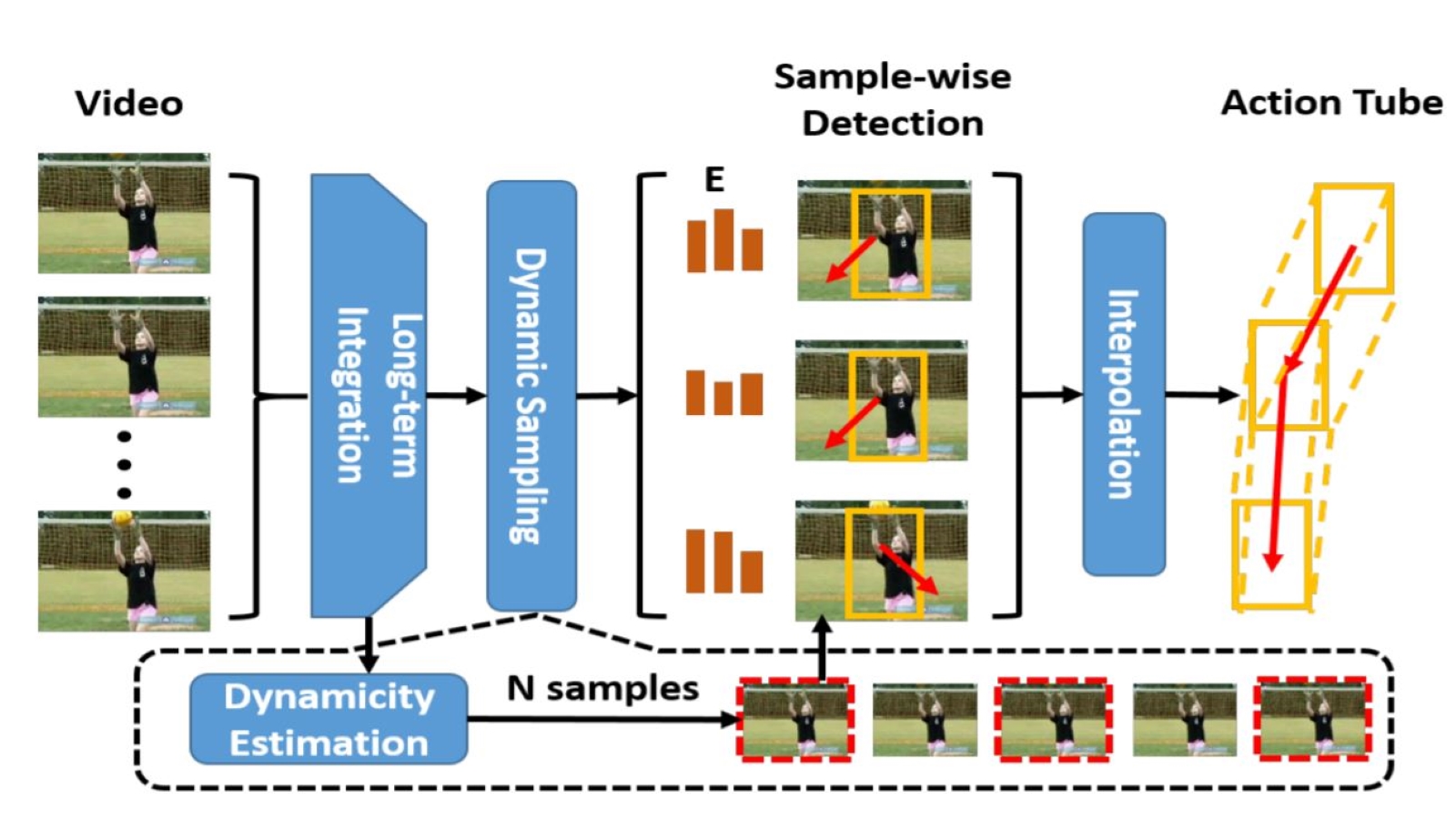
Yuxi Li, Weiyao Lin, Tao Wang, John See, Rui Qian, Ning Xu, Limin Wang, Shugong Xu AAAI, 2020 Spatio-temporal action localization, to localize 3D action tubes in temporal and spatial domain |
|
Hong Kong PhD Fellowship Scheme. 2021 Outstanding Graduate of Shanghai. 2021 Top 1% Bachelor Thesis Award of Shanghai Jiao Tong University. 2021 Sensetime Scholarship. 2020 Finalist winner of MCM. 2019 Nation Scholarship, Ministry of Education of China. 2018 |
|
|
|
1. Great honor to be awarded the bachelor's degree from Shanghai Jiao Tong University, really memorable four years and great thanks for the friends, colleagues and professors. 2. I am fond of Formula 1 and a real Tifosi. Excited to see Ferrari coming back at the beginning of this season and enjoy the battle between Charles Leclerc and Max Verstappen. However, Ferrari never disappoints fans in terms of letting fans disappointed as usual. 3. Here is my best friend Shuangrui, who is really talented and interesting. More than ten years' friendship, great company, marvellous collaboration, memorable encouragement and indispensible shared enjoyment. |
|
Updated at Jun. 2025
Thanks Jon Barron for this amazing template.
|